
Agentic AI - Chapter 2
RAG, the Memory and Context
You didn’t come this far to stop, go Next but here is quick summary
RECAP..
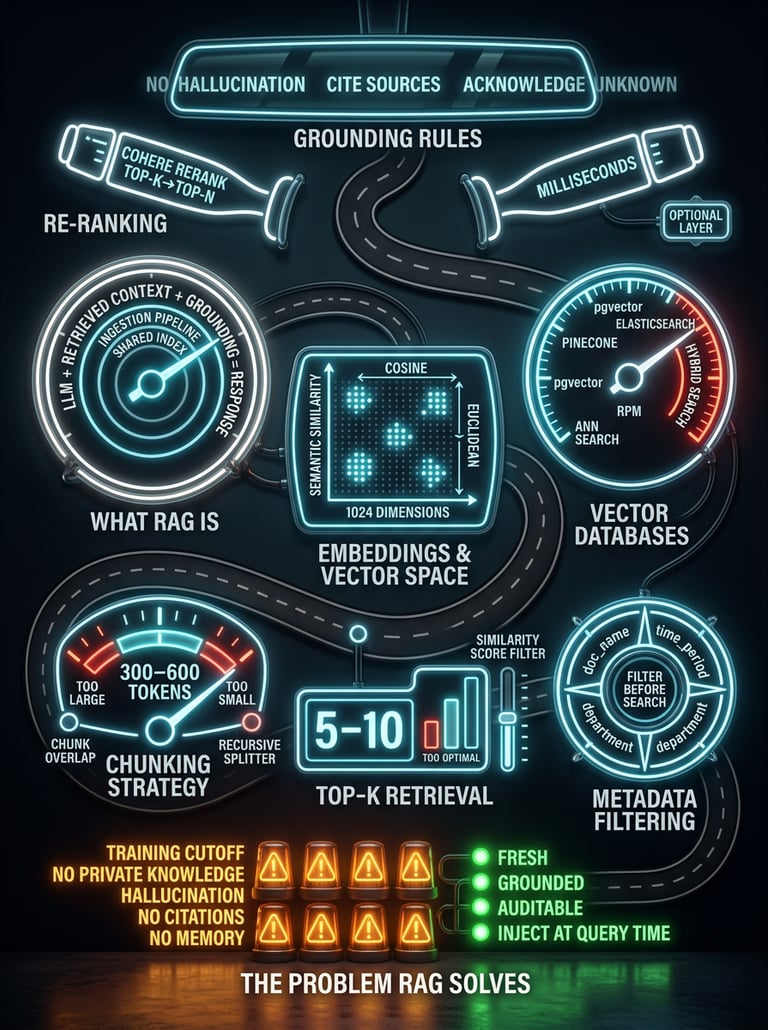
The Problem RAG Solves Training cutoff · No private knowledge · Hallucination · No citations · No memory · Inject at query time · Fresh · Grounded · Auditable
What RAG Actually Is LLM + Retrieved Context + Grounding = Response · Ingestion Pipeline · Query Pipeline · Shared Index · Offline vs Real-time · Separation of concerns
Embeddings & Vector Space Text → Numbers · Semantic similarity · Multi-dimensional · Cosine similarity · Euclidean distance · Context-dependent · Embedding model · 1024 dimensions
Vector Databases Pinecone · Index · Namespace · Record · Vector + Metadata + Text · ANN search · pgvector · Elasticsearch · Hybrid search · Similarity matching
Chunking Strategy 300–600 tokens · Too large = diluted · Too small = fragmented · Recursive splitter · Chunk overlap · Logical unit · POC first · Re-index cost
Retrieval & Top-K Top-K = 5–10 · Too low = incomplete · Too high = noise · Similarity score filter · Cosine similarity · Dynamic parameter · No re-index needed · Tune first
Metadata Filtering Key-value tags · doc_name · time_period · department · Filter before search · Narrow search space · Faster · Cheaper · Higher precision · Library catalog
Re-Ranking Cohere Rerank · Top-K → Top-N · Contextual relevance · Second pass · Post-retrieval · Optional layer · Milliseconds · Add only when needed
Grounding Rules System prompt · Only use retrieved data · No hallucination · Cite sources · Acknowledge unknown · Output format · Compliance · Trust · Behavioral constraint
Full Architecture 5 layers · Source → Ingest → Store → Retrieve → Generate · Tune per layer · Debug by layer · Cost per query · Token economics · POC before scale